Modern web applications need performance
The majority of modern web applications, if not all of them, are utilising some kind of data management and storing solution. Most of these applications are relying on modern database systems such as MySQL or MongoDB to name a few.

As more and more users are moving their workloads online, either in the form of performing simple word processing and light image editing or in heavily CPU and data retrieval bound applications such as BPM solutions for large corporations, "speed and power" (sic) are indispensable.

Modern database solutions have a vast amount of perks for even a seasoned web developer to utilize in order to make her application fly.
Utilizing indexes for faster data retrieval
Indexing stuff for the sake of finding it faster is not a new kid in the block. For example, scholars in the great Library of Alexandria in Egypt have been using a lookup system for quickly finding papers that were interesting to them as back as 280BC. That system was heavily relying on indexing and was designed by Calimachus, a poet, critic and scholar of the time. The name of the system was "Pinakes", translating in English as "Tables".
Is indexing still relevant today ?
Let's start our short journey in indexing by explaining what indexing actually is in a context that may actually be useful for modern day data retrieval solutions developers and not for ancient Alexandria scholars.
Typical database systems are storing data on slow disks where I/O bottlenecks are almost innevitable. Even with modern solid state drives the speed of retrieving raw data out of the disk has not given us yet that "whoosh" moment.

In-memory database solutions are becoming a thing today with Redis and other caching mechanisms and message brokers but they are still a long way for being a fully fledged database system that we can actually store all of our data - largely due to hardware limitations and cost.
Even if we utilize such caching solutions like Redis, there is a certainty that on some occassions the application will have to query the database and then, the database retrieve data that they are stored on disk. So, I/O lag is a thing and we have to make up for that by making our database searches more performant.
Indexes are an incredibly powerful feature of relational databases. In fact, using indexes properly can often improve the performance of your queries by an order of magnitude.
Indexes allow you to “ask questions” without having to search the entire table on disk. They’re really useful for answering “needle in a haystack” type of questions, where you’d otherwise have to look through many rows to pick out only the one that you actually need.
An index is a data structure that’s stored persistently on disk, and is typically implemented as either:
- "B-Tree" -- fast for all sorts of comparisons (>, <, ==)
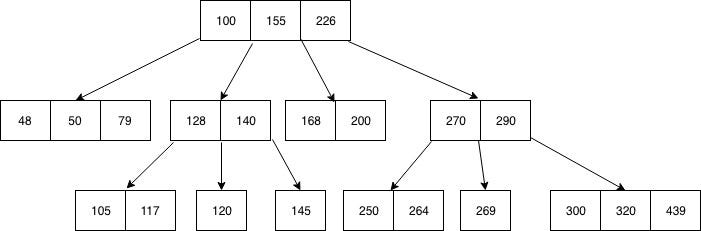
- "Hash Table" -- fast only for equality comparison (==)

Without an index, performing a SELECT ... FROM table WHERE ...; statement requires the DBMS to search through every single row in the table to see if it matches that exact WHERE clause. If you have more than a few hundreds rows in a table - and most modern web applications have millions if not billions - this takes a non-negligible amount of time.

But by adding an index to a column that you frequently run lookups on, you can decrease this amount of time required. Instead of having to scan n rows (where n is the total number of rows in the database), the database can return your query by looking at either log(n) rows (if indexes are implemented as a b-tree) or simply one row (if indexes are implemented as a hash table).
Once you’ve set an index on a particular column, you don’t need to do anything to make subsequent queries use it. The query planner in the DBMS will use that index if it needs to.

Is it all that sugary and sweet ?
What was mentioned above are the stellar reasons of using indexes in your relational database. But, as with everything in this world, there are a few downsides to be aware of. Since the index is stored as a separate data structure, building too many indexes will result in additional space on disk.
One other thing to keep in mind when using indexes is the overhead of index creation and maintenance.
Whenever a new row is added to the table, the index’s data structure must also be updated so that the index remains accurate.
Sacrificing a bit of performance on writes to get much better performance on reads seems a good deal for me.
Thanks for your time, stay safe and sane.